Stockée en ligne, la table précédente serait enregistrée de la façon suivante :
![]()
Une fois les données organisées en colonne, il est possible d’en agréger les attributs afin de compresser davantage la donnée :
![]()
L’éditeur SAP propose quelques recommandations afin de construire une vue performante.
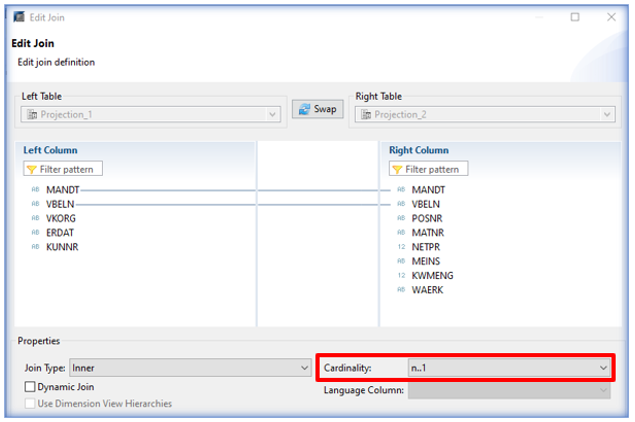
 Le paramétrage des cardinalités lors des jointures : non obligatoire, ce paramètre est cependant requis pour accélérer la recherche. La cardinalité indique le nombre de lignes d’une table qui correspond au nombre de lignes de la table jointe. La correspondance se fait sur une ou plusieurs (n) lignes. Afin d’identifier la cardinalité entre deux tables, l’utilisateur peut s’aider des clés de chaque table qui indiquent un enregistrement unique. En général, un left join entre une table de fait et une table de dimension se dote d’une cardinalité de N à 1.
Le paramétrage des cardinalités lors des jointures : non obligatoire, ce paramètre est cependant requis pour accélérer la recherche. La cardinalité indique le nombre de lignes d’une table qui correspond au nombre de lignes de la table jointe. La correspondance se fait sur une ou plusieurs (n) lignes. Afin d’identifier la cardinalité entre deux tables, l’utilisateur peut s’aider des clés de chaque table qui indiquent un enregistrement unique. En général, un left join entre une table de fait et une table de dimension se dote d’une cardinalité de N à 1.
Illustration : dans le cadre d’une jointure entre une table de commandes client (données d’en-tête) avec une table de description client (nom, adresse…), chaque référence client ne correspond qu’à une seule ligne de description. A l’inverse, chaque description peut être affectée sur plusieurs lignes de la table de commandes puisqu’un même client va effectuer plusieurs commandes.
L’intérêt de la saisie de la cardinalité en termes de performance réside donc dans le fait que lorsque le nom du client (table droite) est affecté à la référence client (table gauche), l’outil sait qu’il peut arrêter de parcourir les autres lignes de la table. Si la cardinalité n’était pas indiquée, il aurait parcouru toute la table, de manière inutile car aucun autre résultat n’aurait été trouvé. Cette opération aurait été effectuée pour chaque enregistrement de la table gauche.
La cardinalité se paramètre dans l’éditeur de jointures :
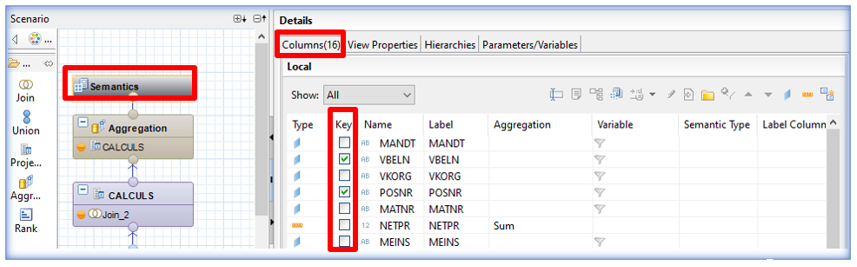
La gestion des clés : paramètre également non obligatoire, il est cependant primordial d’associer les clés dans la couche sémantique de la vue analytique dans un souci de performance. SAP HANA crée ainsi automatiquement des index sur ces champs clé, ce qui est pertinent sachant que SAP HANA ne prend pas en compte la création d’index sur les vues analytiques. Les champs clé d’une table ou d’une vue sont ceux qui permettent l’identification d’une ligne unique. Pour comprendre cette notion, nous pouvons reprendre l’exemple de la table des commandes client, mais cette fois-ci au niveau des postes. Chaque ligne sera unique dès lors que le couple référence commande / référence poste sera lu : les champs clé sont alors identifiés. Les clés d’une vue se paramètrent au niveau sémantique :
La bonne gestion des quantités d’enregistrements : il est primordial de gérer correctement le nombre de lignes dans la construction d’une vue. Deux vues modélisées différemment, mais ayant les mêmes données d’entrée et de sortie, peuvent nécessiter de recourir à des quantités de ressources bien différentes selon la façon dont elles sont construites. Le concepteur doit garder en tête que chaque opération de modélisation doit se faire sur le nombre de lignes le plus petit possible. Cet élément implique différentes recommandations :
- Placer les filtres le plus près possible des tables interrogées
- Encapsuler les tables dans une projection pour filtrer immédiatement les données
- Effectuer les calculs sur le plus petit nombre possible d’enregistrements : en général, dans une projection proche de la sémantique, après filtres et agrégations.
Les jointures de tables sont à effectuer en priorité sur des colonnes clé ou indexées pour accélérer la recherche.
La réutilisation des vues déjà existantes plutôt que de créer un modèle pour chaque besoin. Grâce à la persistance des vues analytiques sur SAP HANA, les calculs n’ont pas besoin d’être opérés à nouveau. C’est également dans cette logique que SAP HANA met à disposition l’objet Star Join, qui consiste à faire graviter des vues de dimension (comprenant des attributs, qui sont des vues sans mesures) autour d’une vue de fait. Au-delà du gain de temps évident au moment de la conception, le gain de performance est immense grâce à la persistance des vues.
Il est donc recommandé de construire des vues de dimension pour modéliser les attributs fréquemment requis, même s’il n’y a que de champs : par exemple, un code de TVA et sa description. L’utilisation des jointures en étoile est vivement recommandée par l’éditeur.