Introduction
SAP Data Warehouse Cloud est constamment mis à jour, et même son nom a récemment changé puisqu’il s’appelle désormais SAP Datasphere. Grâce aux nombreuses fonctionnalités qui sont ajoutées ou bien modifiées, la nouvelle version SAP Datasphere facilite la gestion, la modélisation et le stockage des données pour l’utilisateur.
Parmi les fonctionnalités récemment ajoutées, nous trouvons :
1-ANALYTIC MODELS :
L’une des capacités de SAP Datasphere est de fournir aux utilisateurs une analyse de données exceptionnelle à l’aide des tableaux de bord interactifs, des vues graphiques et des rapports en utilisant diverses sources de données, y compris SAP HANA et d’autres sources de données tierces.
Nous créons généralement des Analytical Datasets pour cette analyse dans le Business Builder et combinons ensuite les vues graphiques déjà créées dans le Data Builder.
Aujourd’hui, grâce aux Analytic Models, il est possible de faire toute cette procédure uniquement dans le Data Builder.
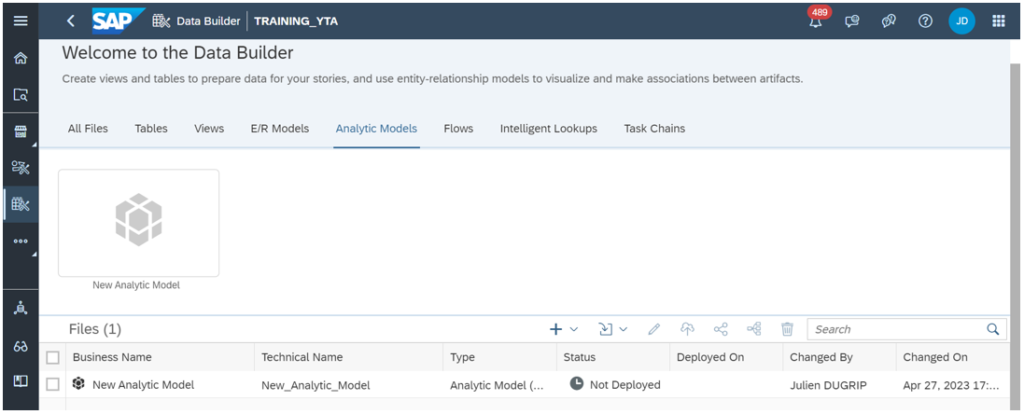
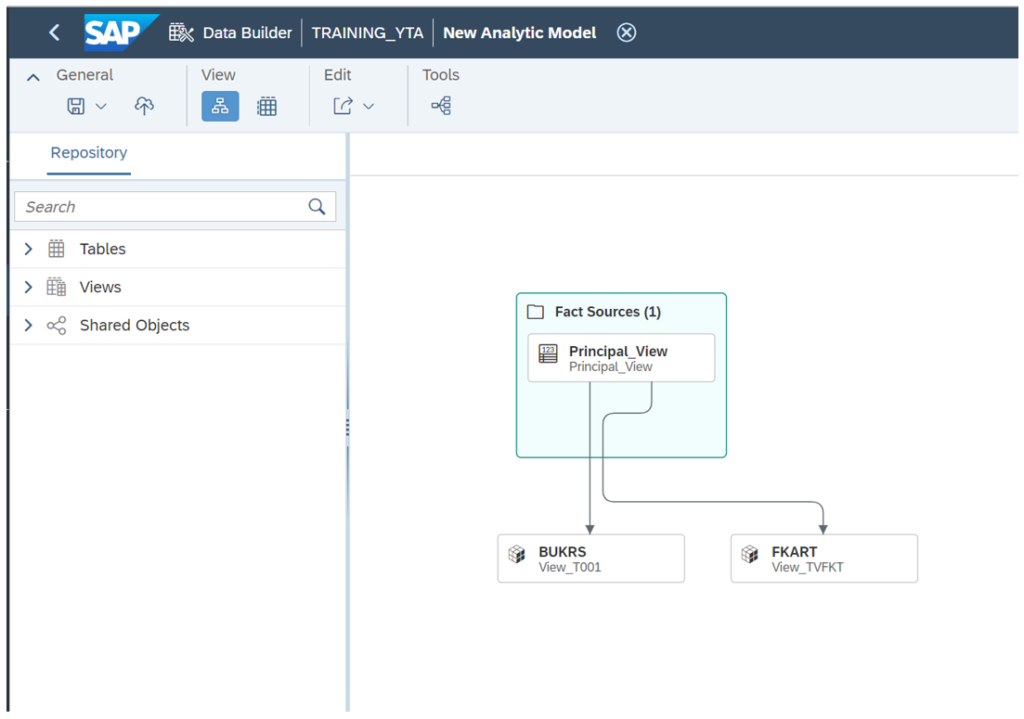
Avec les Analytic Models, les utilisateurs peuvent facilement créer et gérer des flux de données qui automatisent le processus de préparation, de transformation et de chargement des données. Cela facilite l’intégration de données provenant de différentes sources, le nettoyage et la transformation de données, et finalement, leurs chargements dans des Datasets.
La principale différence entre un Analytic Model et un Analytical Dataset c’est que le deuxième est un type spécifique de dataset optimisé pour une analyse simple. Cependant, l’Analytic Model est un concept plus large qui inclut plusieurs datasets conçus pour des tâches d’analyse plus complexes et plus avancées.
Inscrivez-vous à la newsletter Rapid Views !
Soyez notifiés de nos derniers articles de blog, de nos prochains webinars et nos actualités !
2-REPLICATION FLOW :
La fonctionnalité Data Flow que nous connaissons, est utilisée pour copier des données d’un système source vers un système cible tel que SAP Datasphere. Les données peuvent provenir de différents objets d’un système source, qu’il s’agisse d’un système sur site, d’un système basé sur le cloud, d’un système SAP, d’un système non SAP ou de différentes bases de données. Elle permet d’appliquer des transformations de données complexes et de les intégrer dans une seule table de sortie à la fois.
Cependant, les Replication Flows offrent des options de projection de mapping simples pour plusieurs objets à la fois. Par conséquent, nous pouvons faire des réplications un-à-un des données provenant de vues CDS, de tables ou de fournisseurs ODP.
Comme les Data Flows, les Replication Flows sont faciles à utiliser grâce à une interface user-friendly car ils répliquent les données sans demander à l’utilisateur d’écrire de code ou de scripts complexes. Elle permet également la réplication de données instantanée et planifiée, selon le besoin de l’utilisateur.
Pour voir la fonctionnalité Replication Flow dans SAP Datasphere, il faut d’abord s’assurer que le rôle « SAP Datasphere Integrator » est attribué à votre utilisateur.
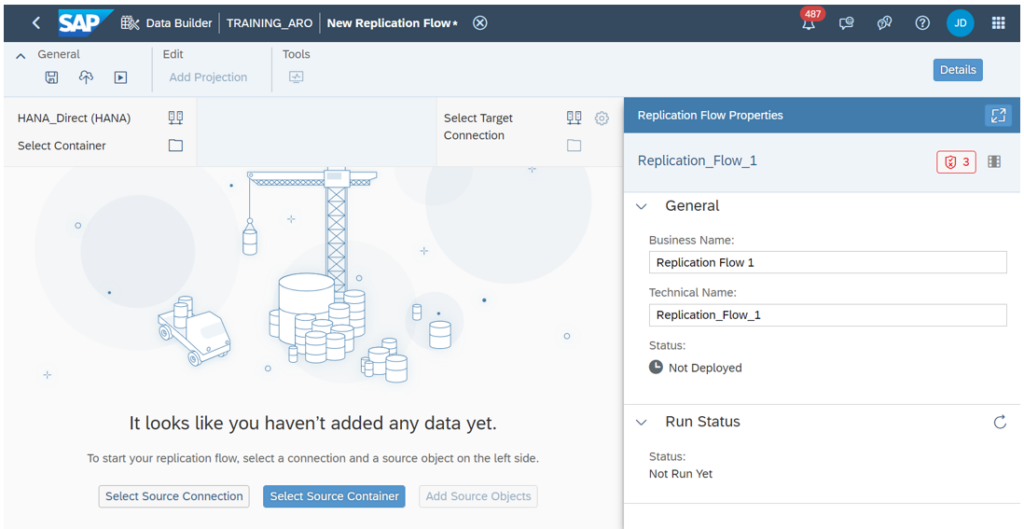
Ensuite vous procédez à la création d’un nouveau Replication Flow. Vous spécifiez le système source et le système cible. Le système source peut-être n’importe quel système contenant des données que vous souhaitez répliquer, qu’il s’agisse d’un système on-premise, d’un système basé sur le cloud, d’un système SAP, d’un système non-SAP ou d’une base de données. Dans notre cas, le système cible est SAP Data Warehouse Cloud.

En cliquant sur « Select Source Connection », vous choisissez la connexion source dans la liste des options disponibles dans SAP Datasphere.

Après vous choisissez un container d’objets :
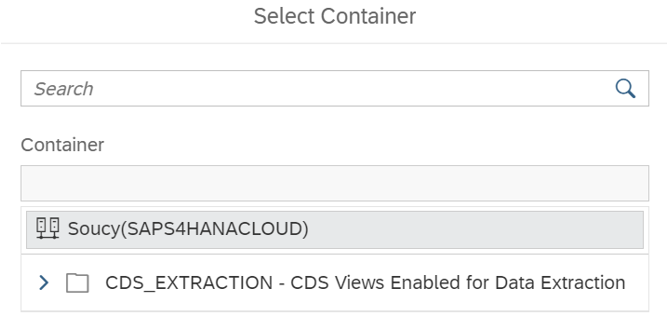
Puis vous sélectionnez les objets que vous souhaitez répliquer :
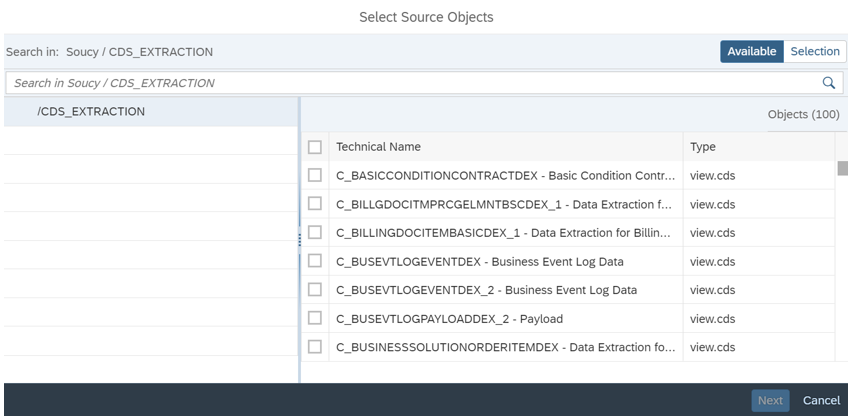
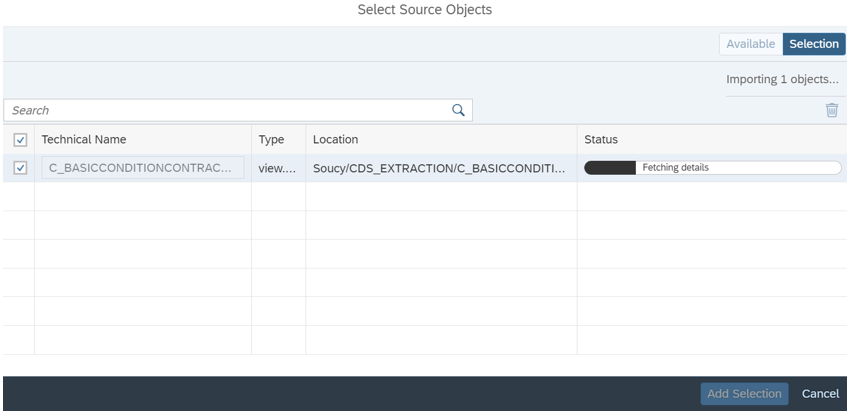
En passant par les mêmes étapes, nous sélectionnons une connexion cible et nous passons au mapping des objets du système source avec les objets préalablement créés dans le Data Builder. Ce mapping définira la manière dont les données seront répliquées dans le système cible.
Finalement, vous pouvez choisir le mode de réplication, instantané ou programmé.
3-CATALOG :
Le Catalogue est un référentiel centralisé de tous les objets de données et transformations disponibles dans un espace particulier. Il fournit une vue globale de tous les objets SAP Dataphere. C’est le seul endroit où les utilisateurs peuvent découvrir, comprendre et gérer leurs objets.
Pour avoir cette vue globale, nous commençons d’abord par la création de la connexion SAP Datasphere et SAP Analytics Cloud sur l’onglet Monitoring.
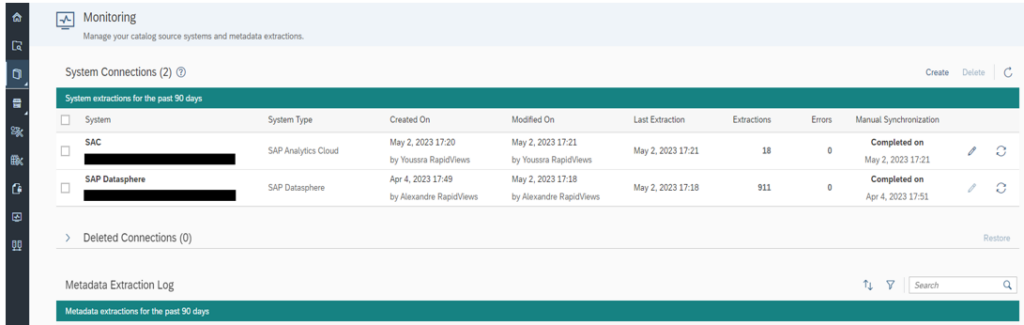
C’est dans cet onglet que nous trouvons les sources de données, les connexions et le log des extractions.
En faisant la synchronisation manuelle, nous retrouvons le répertoire centralisé de la manière suivante :
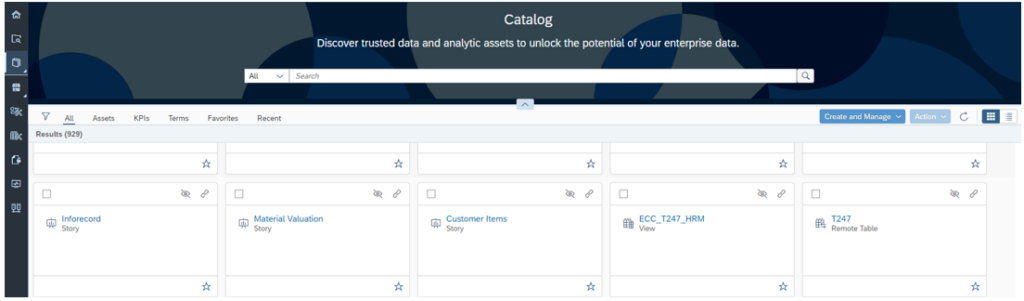
Ce catalogue se compose d’une barre de recherche où les utilisateurs peuvent trouver ce dont ils ont besoin, tels que des vues, des rapports et des définitions soit des colonnes, des termes ou des KPIs. Ils peuvent notamment rechercher par nom, description ou tags et filtrer les résultats par type de données, source de données ou autres attributs.
Ainsi, le catalogue permet aux utilisateurs de connaître la structure et la qualité de leurs objets grâce aux Data Lineages et aux dépendances. Par conséquent, l’utilisateur peut prendre des décisions raisonnables et justifiées sur la consommation des données.
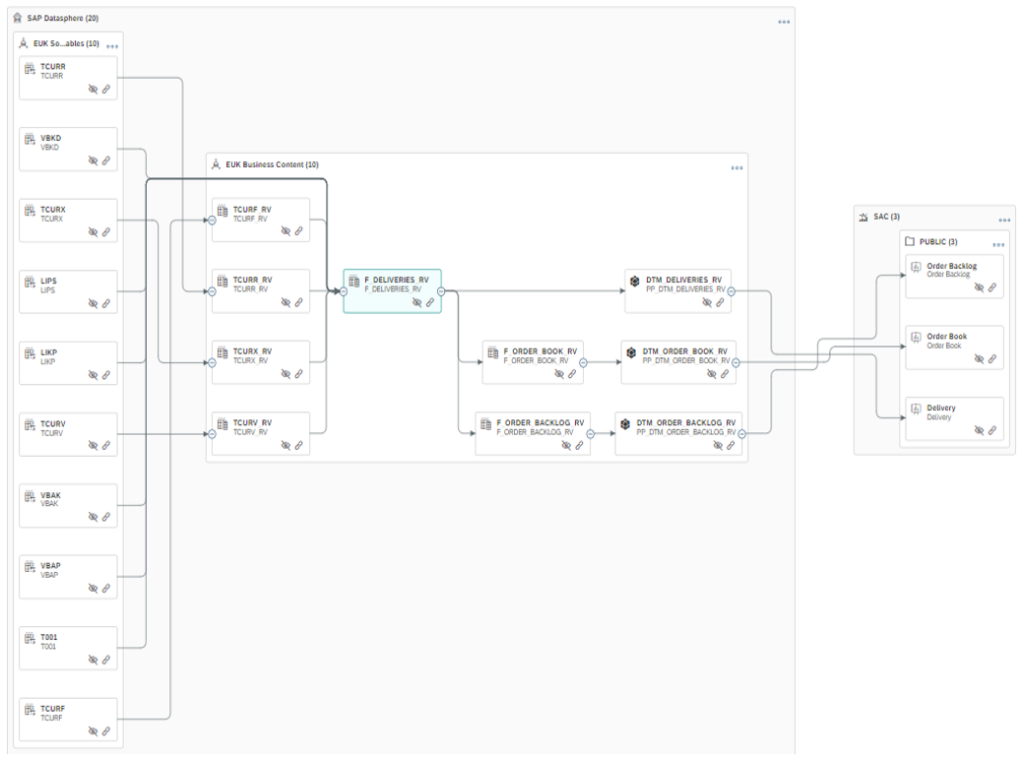
Il donne également à l’administrateur le droit de contrôler les utilisateurs et de gérer leurs activités. Il peut limiter la visibilité et modifier le pourcentage d’accès aux données.
Conclusion
Cet article fournit une vue d’ensemble uniquement des fonctionnalités nouvellement ajoutées dans SAP Datasphere. Au cours de chaque période de mise à jour, plusieurs fonctionnalités sont modifiées et améliorées afin de rendre l’expérience des utilisateurs plus efficace en temps et en effort.










































