Introduction
Certaines données de l’ERP SAP ne sont pas toujours stockées dans la base HANA de l’ERP. L’ERP les recalcule à chaque interrogation, ou besoin. Lorsque nous souhaitons avoir ces informations rapidement, ou dans le monde de la Business intelligence, il n’est pas toujours possible de lancer des calculs long ou couteux sur les données, nous devons pouvoir accéder directement à la donnée déjà calculée et stockée.
Dans la base HANA pour des besoins en Business Intelligence il est intéressant de pouvoir planifier des jobs permettant de stocker des données dans des tables personnalisées afin de répondre à certains besoins.
Nous pouvons dans l’outil SAP HANA Studio planifier de manière récurrente des tâches qui exécutent des procédures ou des scripts SQL afin de charger les résultats dans des tables personnalisées (comme un trigger). Ces opérations peuvent êtres répétées et planifiées sur un intervalle de temps.
Toutes les étapes de création des tables personnalisées, de création des jobs et des scripts SQL sont effectuées dans l’outil SAP HANA Studio, à l’exception de l’activation et du suivi des logs d’exécution de ces jobs. Pour la partie exécution, nous accédons au composant web XS Job Scheduler de SAP HANA via cette URL : http://<WebServerHost>:<SAPHANAinstance>/sap/hana/xs/admin/job
Création d’une table personnalisée et historisation de données quotidiennes
Prenons l’exemple du scénario suivant. Un client a besoin d’un tableau contenant l’historique des quantités de stock pour chaque jour, ainsi que le numéro de l’article, l’usine et l’emplacement de stockage correspondant. Ceci afin de pouvoir comparer et suivre jour après jour l’évolution de ses stocks.
Pour répondre à ce besoin, nous devons passer par les étapes suivantes :
- Préparer les données initiales à stocker à partir de notre système source S4 HANA
- Créer une vue de calcul dans SAP HANA Studio permettant le calcul des données
- Créer une table pour le stockage final des données
- Créer une procédure stockée dans SAP HANA Studio pour l’exécution du calcul
- Créer un XS Javascript File et un XS Job Scheduler File pour la planification
- Activer le XS Job Scheduler et consultez le log d’exécution
ETAPE 1 : Préparation des données initiales dans SAP HANA Studio
Ici, nous créons une table nommée « PRIMARY » qui lit et stocke les données recherchées de la table MARD. Nous ne pouvons pas appliquer des changements à cette table car elle fonctionne en mode « lecture seule ».
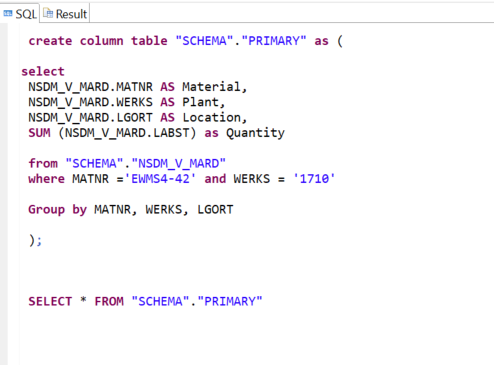
ÉTAPE 2 : Création d’une vue de calcul dans SAP HANA Studio
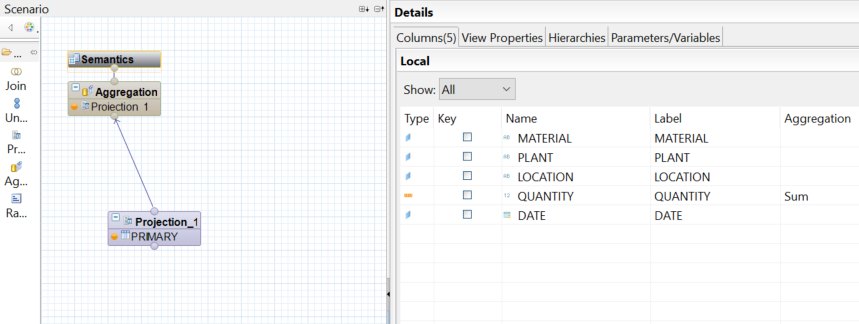
Pour déplacer ces données vers une table modifiable, nous créons une vue de calcul de type Cube « VUE_STOCK » basée sur la table « PRIMARY ».
Inscrivez-vous à la newsletter Rapid Views !
Soyez notifiés de nos derniers articles de blog, de nos prochains webinars et nos actualités !
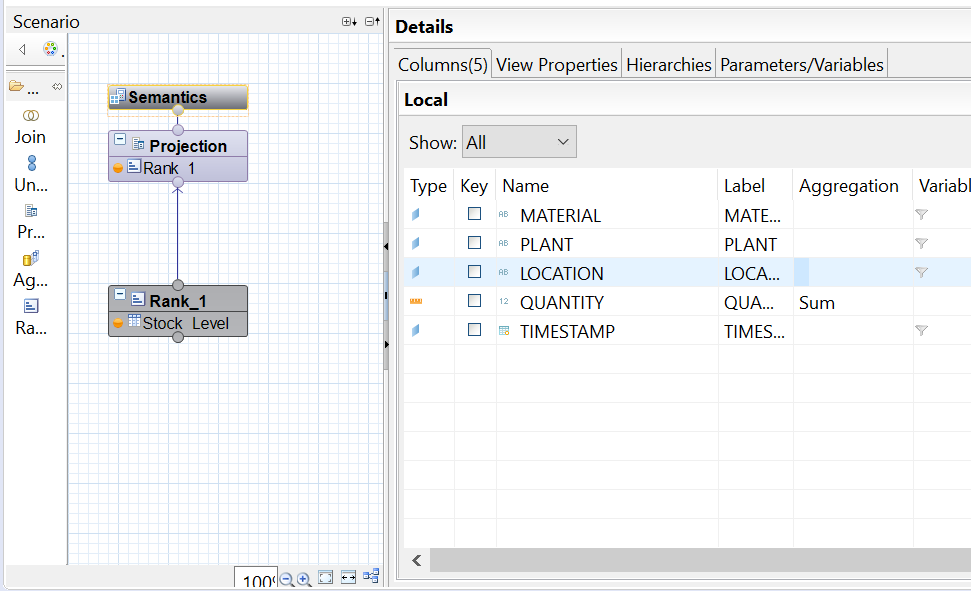
ÉTAPE 3 : Création d’une table pour le stockage des données dans SAP HANA Studio
Ici, nous créons la table « Stock_Level » qui va contenir les données finales souhaitées dans le cas client, ainsi qu’un Timestamp pour l’historisation de la donnée.

ÉTAPE 4 : Création d’une procédure stockée dans SAP HANA Studio
Pour remplir la table « Stock_Level », nous devons construire une procédure « StockProced » qui ajoutera les nouvelles lignes en provenance de la vue « VUE_STOCK » dans cette table à chaque exécution du job.
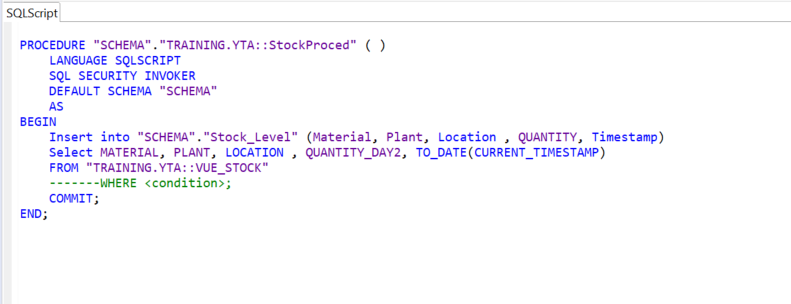
ÉTAPE 5 : Création d’un XS Javascript File et XS Job Scheduler File dans SAP HANA Studio
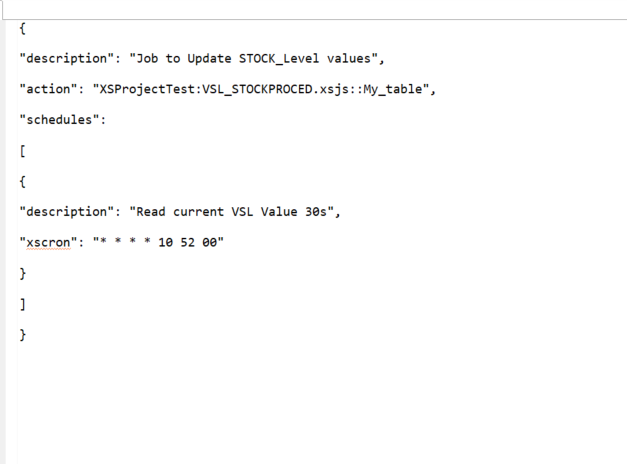
Maintenant nous allons construire le script « VSL_STOCKPROCED » permettant d’appeler cette procédure et de l’exécuter, donc nous avons besoin d’un nouveau XS Javascript File créé à partir du repository de SAP HANA Studio. Vous devez au préalable avoir dans le repository de SAP HANA Studio un package. Dans notre exemple celui-ci s’appelle « XSProjectTest ».
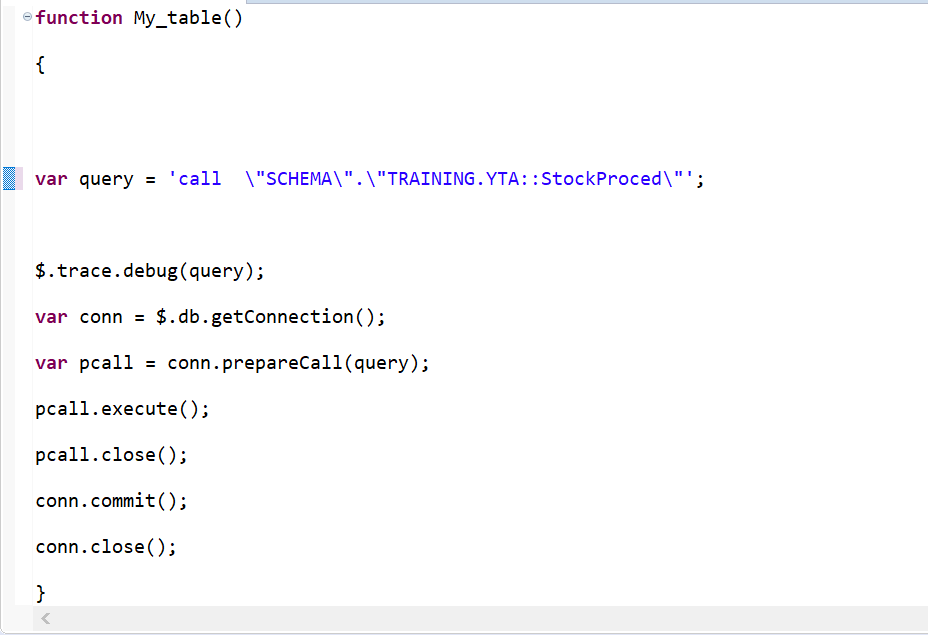
Ensuite pour planifier l’exécution de ce job, nous créons cette fois-ci un nouveau XS Job Scheduler « VSL_STOCKPROCED_JOB » dans le même package « XSProjectTest » du repository SAP HANA Studio.
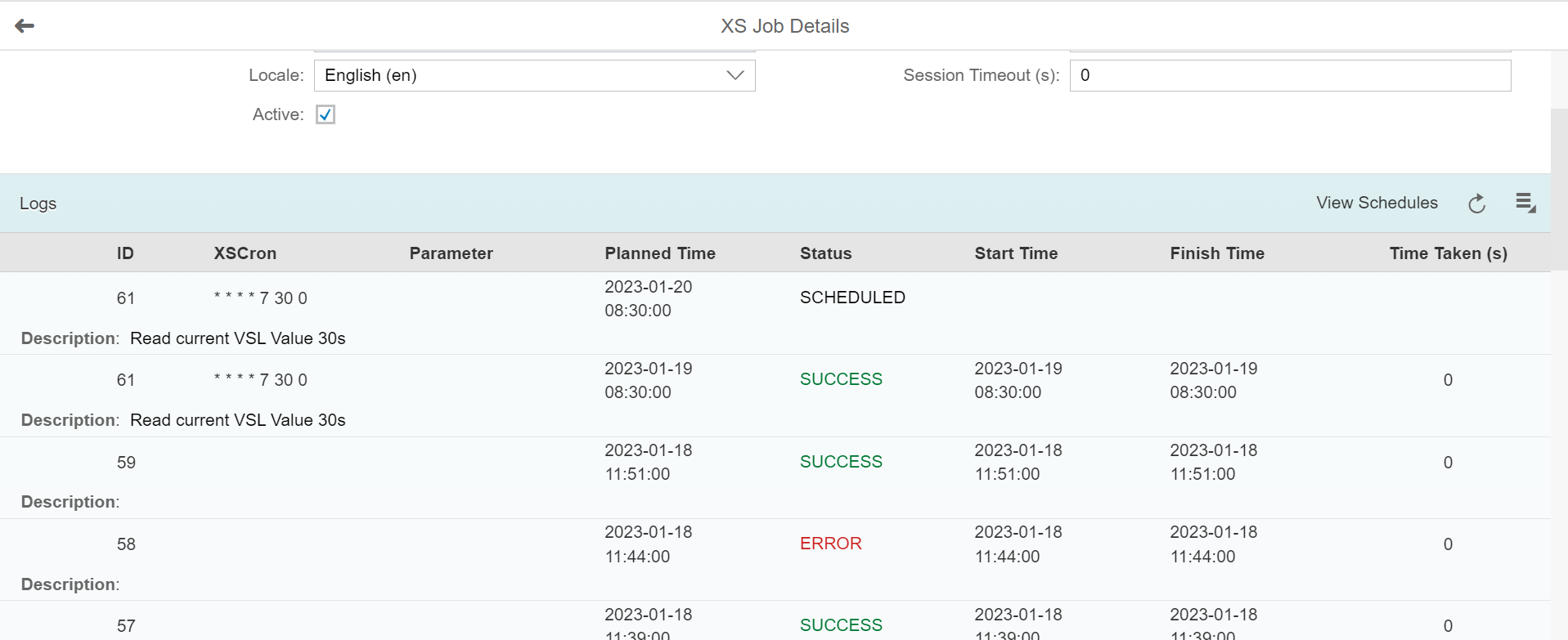
ÉTAPE 6 : Activation du XS Job Scheduler et consultation des logs
Enfin pour activer et lancer le Job Schedule, nous accédons au site web précédemment mentionné « http://<WebServerHost>:<SAPHANAinstance>/sap/hana/xs/admin/jobs. » et nous trouvons bien notre Job « VSL_STOCKPROCED » dans le XS Job Dashboard :
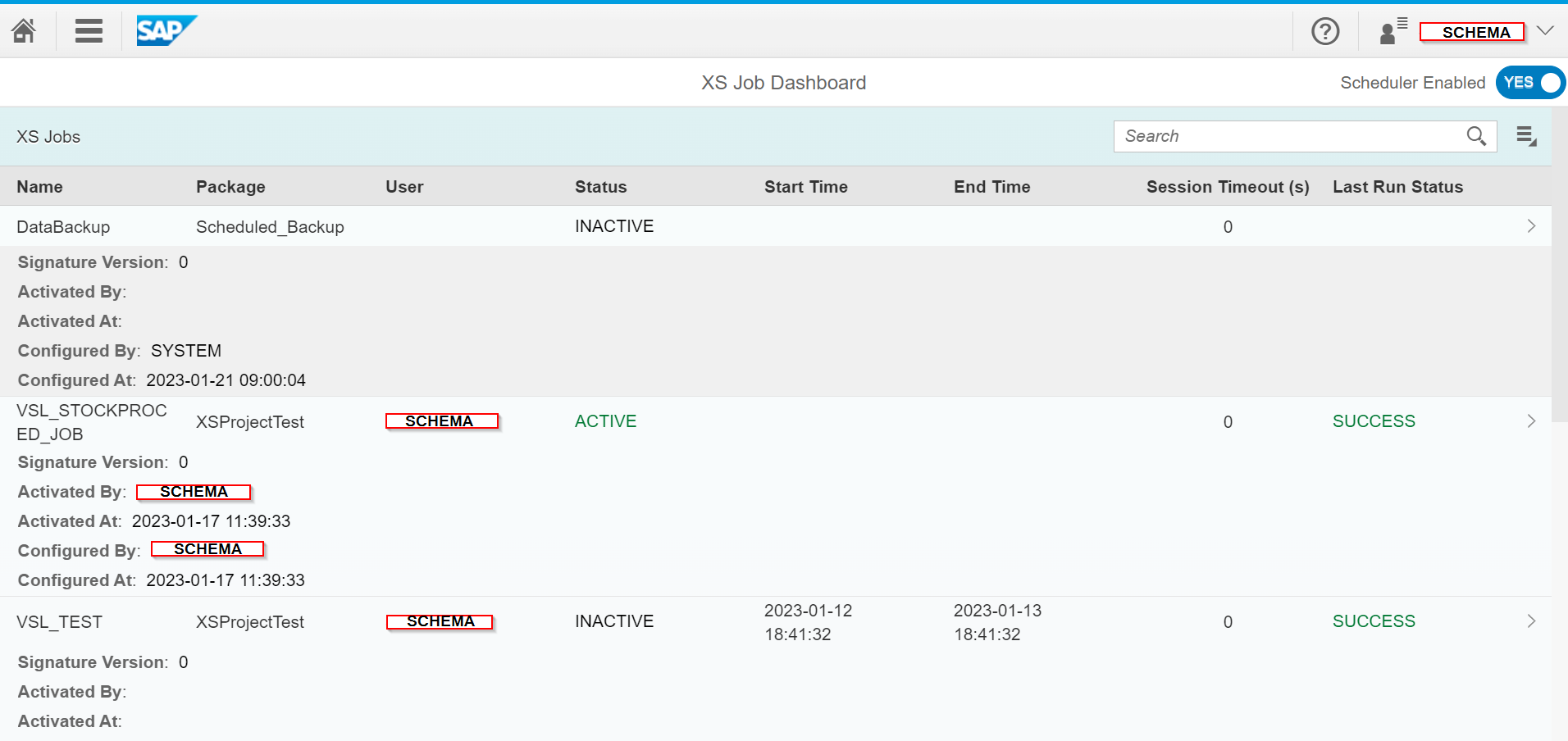
La ligne qui nous intéresse dans notre exemple est celle-ci-dessous :
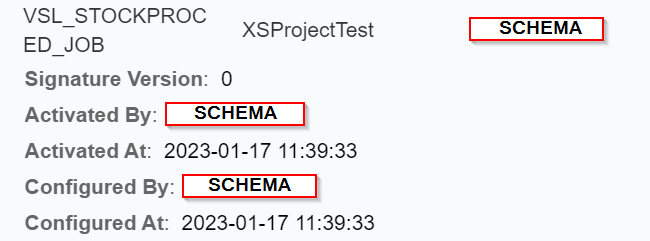
En cliquant sur ce Job, nous retrouvons la partie de configuration ou nous devons cocher la case « Active » pour que le Job passe dans le statut ci-dessous et soit opérationnel :

Après l’exécution du job, nous avons les résultats suivants dans la table « Stock_Level » :
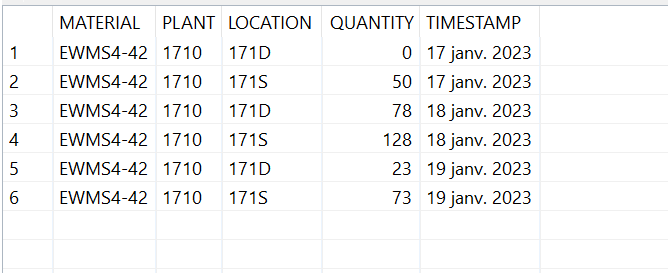
Ci-dessous le log de suivi :
Visualisation des données stockées
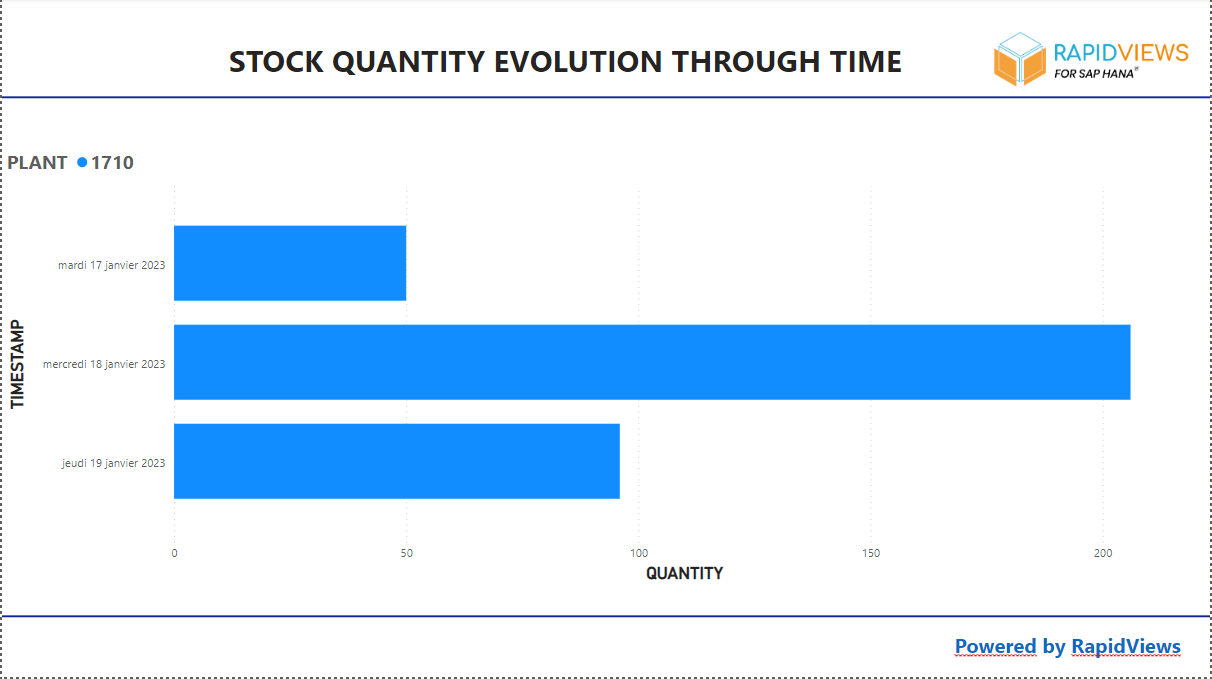
Pour pouvoir utiliser les données finales, dans cet exemple nous avons connecté l’outil de reporting Power BI à notre base HANA.
Dans SAP HANA Studio, une vue de fait « F_STOCK_DATA » basée sur la table de stockage « Stock_Level » a été créé :
Dans le rapport Power BI nous avons importé le contenu de la vue « F_STOCK_DATA » via une connexion HANA :
Conclusion
Dons cet article nous avons montré que la base de données HANA n’est pas qu’une simple base de données de stockage. Grâce à ses fonctionnalités avancées nous pouvons, calculer, historiser, agréger et stocker de l’information dans des tables spécifiques. Ces opérations peuvent êtres planifiées et exécutées de manière automatique via des jobs.
Ces jobs peuvent aussi vous permettre de transformer les données (comme un trigger), ou d’exécuter toute autre opération dans votre base de données SAP HANA.
Ces données transformées, stockées, historisées, peuvent ensuite être utilisées dans n’importe quel outil de restitution.


