Introduction
Some SAP ERP data is not always stored in the ERP’s HANA database. The ERP recalculates it every time it is queried or needed. When we want to have this information quickly, or in the world of Business Intelligence, it is not always possible to launch long or expensive calculations on the data, we must be able to directly access the data already calculated and stored.
In the HANA database for Business Intelligence needs, it is interesting to be able to plan jobs allowing to store data in customized tables in order to meet certain needs.
In the SAP HANA Studio tool, we can recurrently schedule jobs that execute SQL procedures or scripts to load results into custom tables (like a trigger). These operations can be repeated and scheduled over a time interval.
All the steps of creating custom tables, creating jobs and SQL scripts are done in the SAP HANA Studio tool, except for activating and monitoring the execution logs of these jobs.
For the execution part, we access the SAP HANA web component XS Job Scheduler via this URL: http://:/sap/hana/xs/admin/job
Creation of a custom table and history of daily data
Consider the following scenario. A customer needs a table containing the history of the stock quantities for each day, as well as the item number, the factory and the corresponding storage location. This is to be able to compare and monitor the evolution of his stocks day by day.
To meet this need, we need to go through the following steps :
- Prepare the initial data to be stored from our S4 HANA source system
- Create a calculation view in the SAP HANA Studio to calculate the data
- Create a table for the final data storage
- Create a stored procedure in the SAP HANA Studio to run the calculation
- Create an XS Javascript File and an XS Job Scheduler File for scheduling
- Activate the XS Job Scheduler and view the execution log
STEP 1 : Prepare initial data in SAP HANA Studio
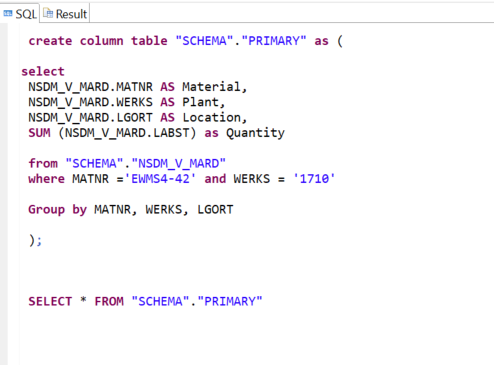
Here, we create a table named “PRIMARY” that reads and stores the data sought from the MARD table. We cannot apply changes to this table because it is running in “read only” mode.
Subscribe to the Rapid Views Newsletter !
Stay up to date with our latest blog posts, upcoming webinars and news!
STEP 2 : Create a calculation view in the SAP HANA Studio
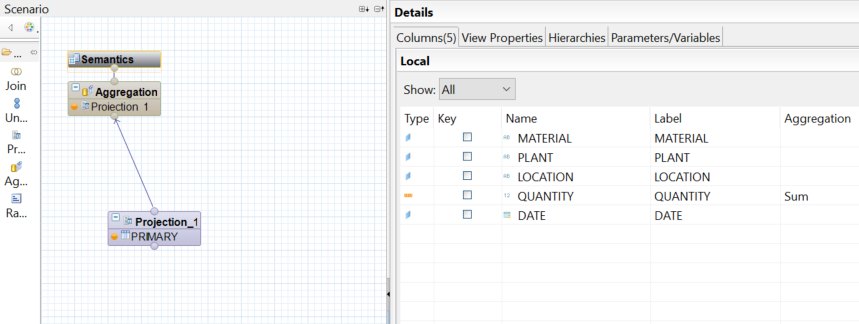
To move this data to an editable table, we create a calculation view of type Cube “VUE_STOCK” based on the “PRIMARY” table.
STEP 3 : Create a table for storing data in the SAP HANA Studio
Here we create the table “Stock_Level” which will contain the final data desired in the customer case, as well as a timestamp for data historization.

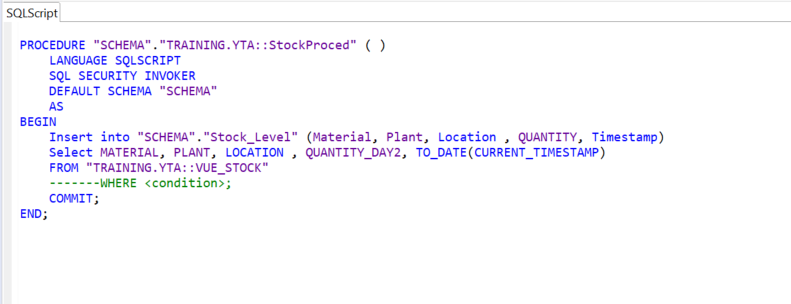
STEP 4 : Create a stored procedure in the SAP HANA Studio
To populate the “Stock_Level” table, we need to build a “StockProcedure” that will add the new rows from the “STOCK_VIEW” to this table each time the job is run.
STEP 5 : Create an XS Javascript File and XS Job Scheduler File in SAP HANA Studio
Now we will build the script “VSL_STOCKPROCED” to call this procedure and execute it, so we need a new XS Javascript File created from the SAP HANA Studio repository. You must first have a package in the SAP HANA Studio repository. In our example this is called “XSProjectTest”.
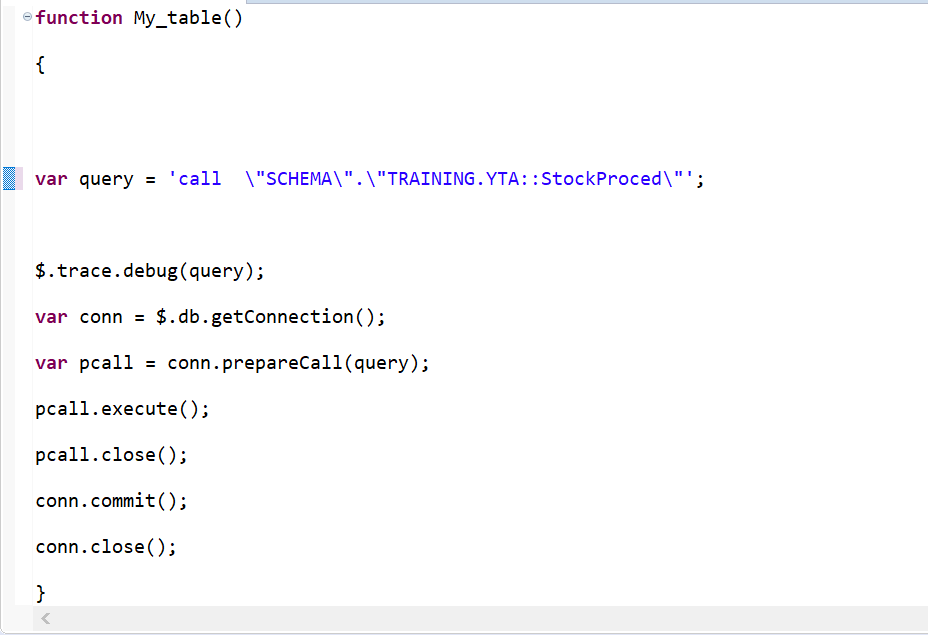
Then to schedule the execution of this job, we create this time a new XS Job Scheduler “VSL_STOCKPROCED_JOB” in the same “XSProjectTest” package of the SAP HANA Studio repository.
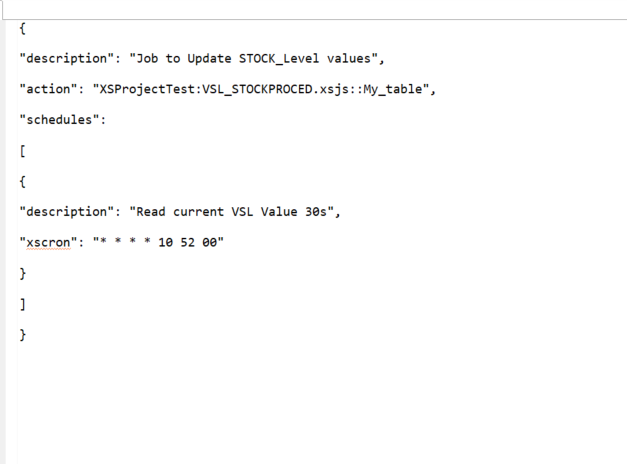
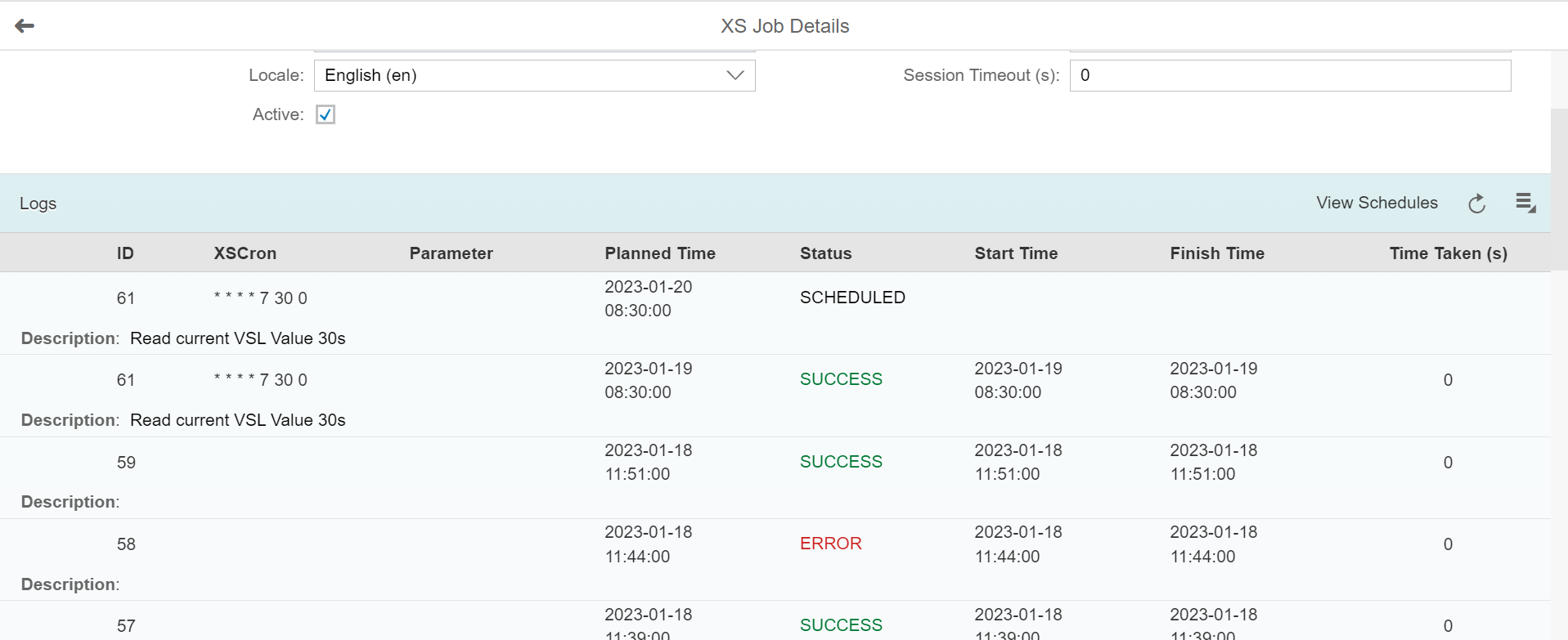
STEP 6 : Activating the XS Job Scheduler and viewing the logs
Finally, to activate and launch the Job Schedule, we access the previously mentioned website « http://:/sap/hana/xs/admin/jobs. » and we find our Job “VSL_STOCKPROCED” in the XS Job Dashboard:
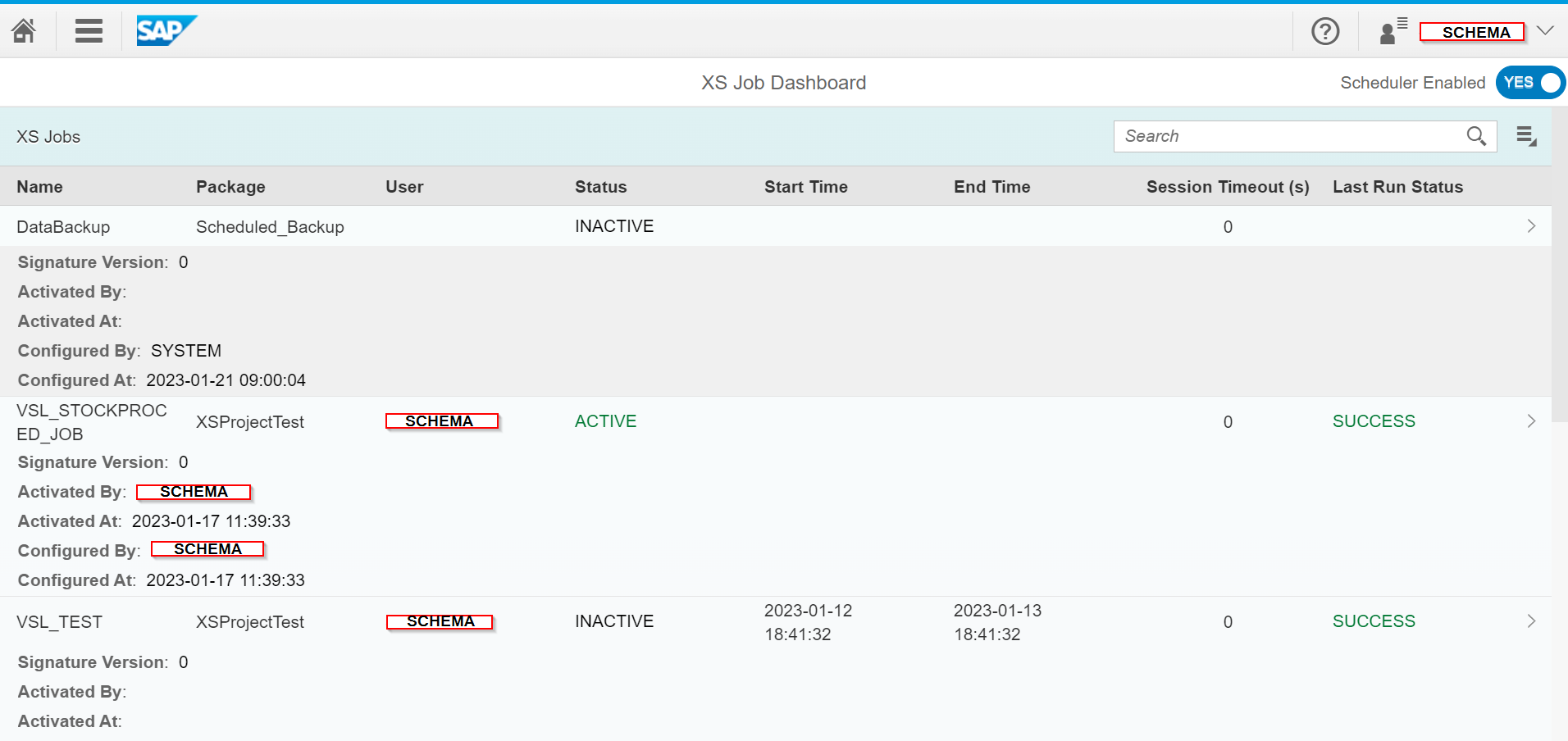
The line of interest in our example is the one below :
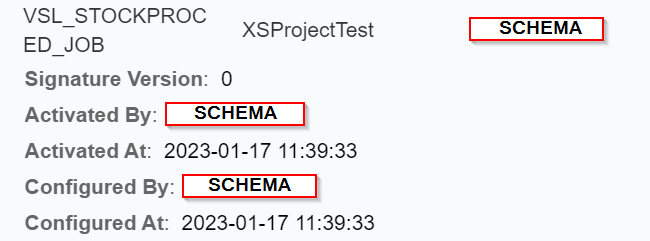
By clicking on this Job, we find the configuration part where we have to check the “Active” box so that the Job passes in the status below and is operational :

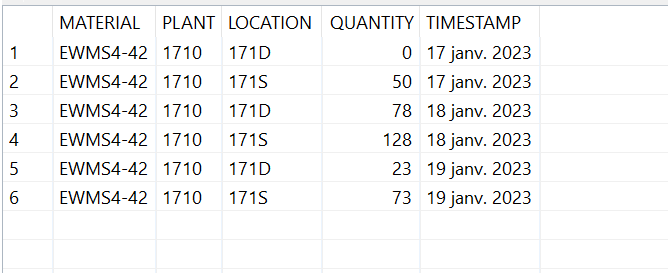
After running the job, we have the following results in the “Stock_Level” table :
Below is the monitoring log :
Visualisation of stored data
To be able to use the final data, in this example we connected the Power BI reporting tool to our HANA database.
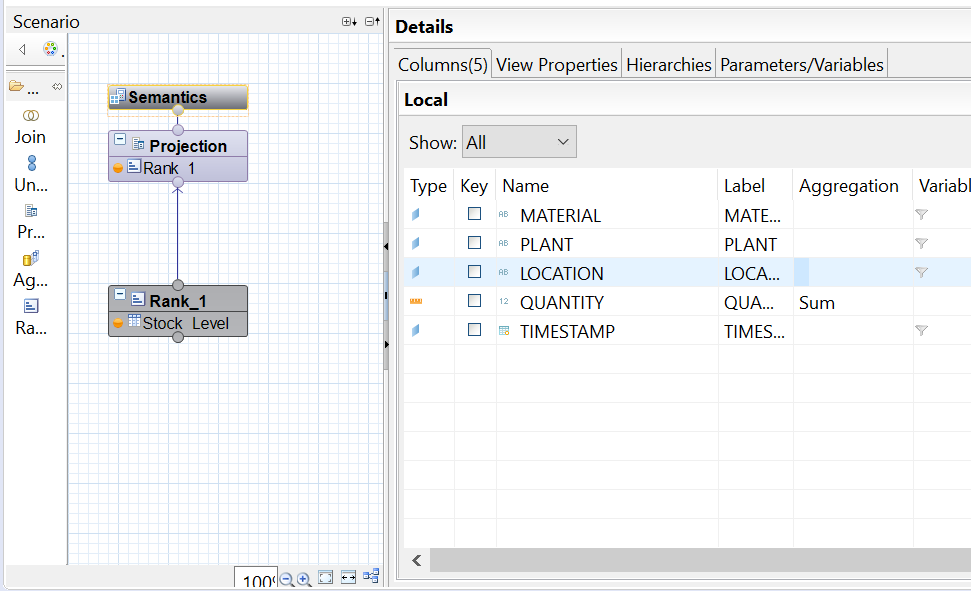
In the SAP HANA Studio, a factual view “F_STOCK_DATA” based on the storage table “Stock_Level” was created :
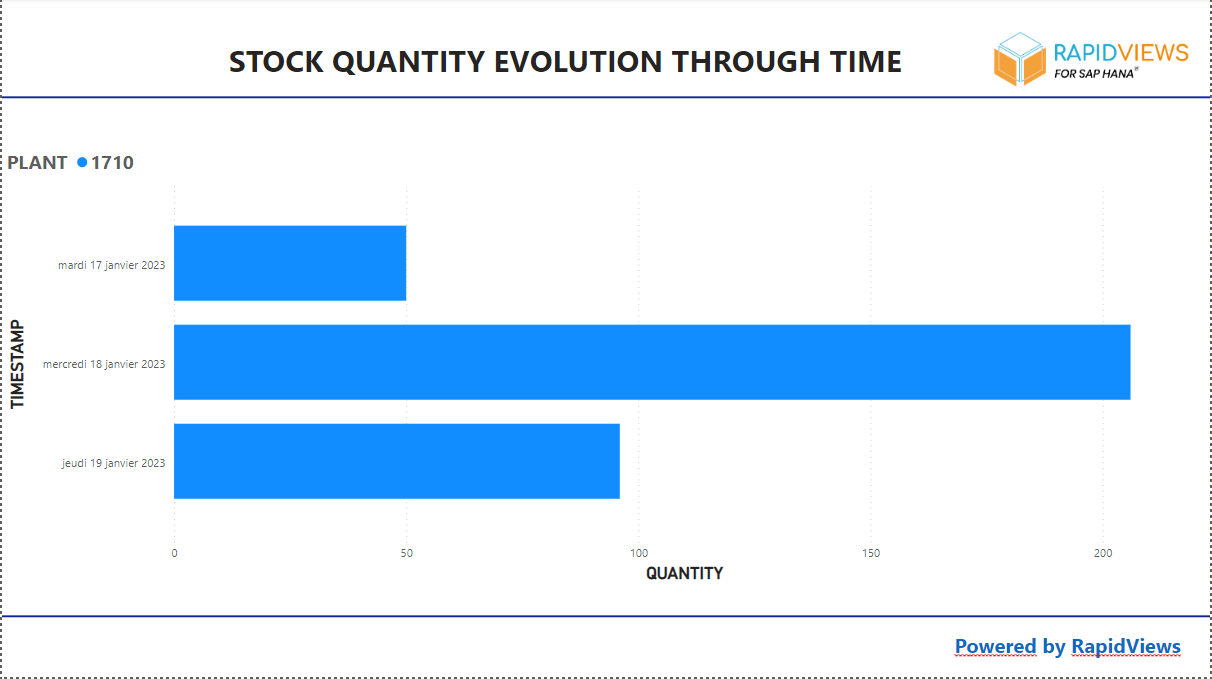
In the Power BI report we imported the contents of the “F_STOCK_DATA” view via a HANA connection :
Conclusion
In this article we have shown that the HANA database is not just a storage database. Thanks to its advanced features we can calculate, historise, aggregate and store information in specific tables. These operations can be scheduled and executed automatically via jobs.
These jobs can also allow you to transform data (like a trigger), or perform any other operation in your SAP HANA database.
This transformed, stored and historical data can then be used in any retrieval tool.


